
Artificial intelligence used to mean exploring possibilities. Now CIOs must deliver results.
Machine learning has evolved into a core business tool. As an example, at a recent meeting for the Capital Markets Credit Analysts Society, literally every bank, rating agency, and regulator responded that they use or are building natural language processing applications.
The need for results means organizing delivery differently. Many first-generation projects jumped into algorithms and technology. We reverse the previous approach by precisely defining the business question, understanding the data generating process, and aligning the entire business.
Second generation AI applications, sponsored by business rather than IT, show patterns. Sponsors wants predictability. They do not want to hear “it depends” about the number of labeled examples required in training data sets or broad estimates on time to reach production-ready models.
Next, applications are shifting from replicating human decisions to more nuanced integration of people, legacy applications, and machines. We see machine learning combined with trusted legacy business logic, replacing repetitive tasks to free analysts for valuable thinking, and summarizing large volumes of documents and data to accelerate human judgment.
Based on experience delivering complex projects, the Machine Intelligence methodology works across business functional areas to:
- Lead change, understanding, and alignment
- Increase predictability
- Form enduring capabilities
The approach consists of three stages. Tasks within a stage can start in parallel.
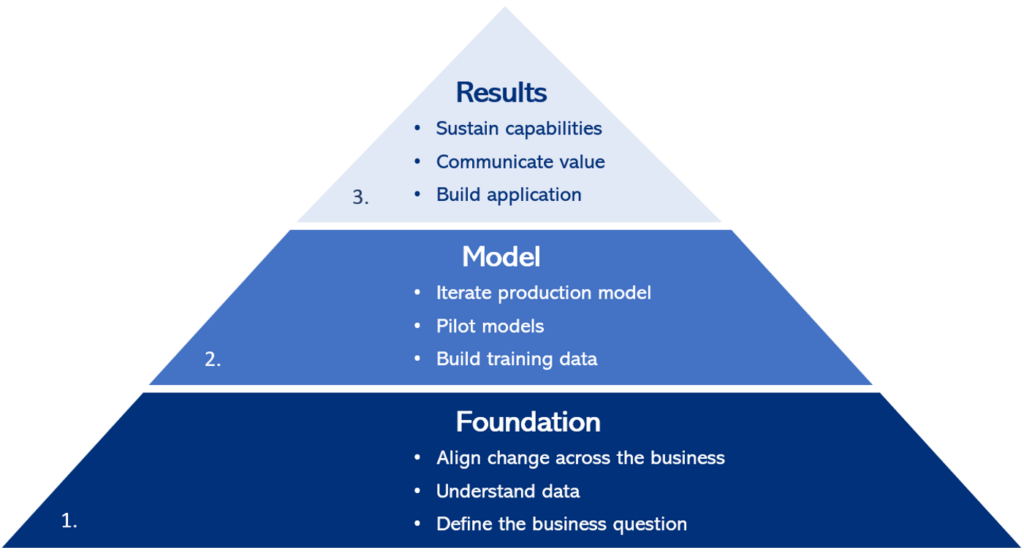
1. Foundation
- Define the business question.
Start with workshops and readings to ensure that sponsors and team members across functional areas understand the data science process. At root, machine learning is simple: models reproduce how examples in training data answer business questions. Quality training data produces quality results.
Next, set precise and actionable business questions. For example, next best action and next best offer are related but distinct business questions. In practice, distinctions are subtler. For example, with a retail securities broker/dealer, we discussed deciding whether to take the other side of an order or pass it through to the market as well as deciding when and how to hedge a position. These are essentially the same question but require very different data and models.
Building the business case is outside the scope of this methodology. However, once a decision is made to act, then the team should confirm facts showing precisely how answering the business question generates the intended operating and financial results.
- Align change.
Identify business and regulatory needs that affect the choice of algorithms and design of training data, such as explainability and social equity. Importantly, decide if a solution requires every decision must be optimal, such as radiology, or if a confident estimate is sufficient, such as for consumer marketing.
For example, we advised a client analyzing media to determine how stakeholders view listed companies. Initially, the team expected that accurately replicating human analysts would suffice. However, even 99% accuracy on tens of millions of articles and social media posts meant that a meaningful number of negative messages could slip through. The resulting solution combines rules with deep learning. Rules lack nuance but deterministically score every media item. The solution then averages rule results with deep learning.
People often expect machines to be significantly more accurate than humans. The black box nature of machine learning means people need a big jump in accuracy to trust models. For example, a company piloted a natural language application at a credit card call center. The legacy system “contained” 67% of calls, meaning calls were resolved without reaching a human representative. By contrast, the card issuer did not trust machine learning until it reached 95% containment.
Assign responsibilities for each functional area. Emphasize business rather than IT ownership:
- Product management: take charge of building training data. Learn the different types of algorithms. Be responsible for model effectiveness.
- Finance: plan capex for cloud while accepting that initial estimates can be unpredictable. Learn concepts such as reserving cloud capacity to reduce cost.
- Sales: contribute time for building training data from people who understand customer behaviors.
- Legal and Compliance: define protocols to achieve fairness in consumer-facing models.
- Understand the data.
Models forecast what happens in the real world, so project teams need to deeply understand how the real world works. Expect to spend significant time understanding the data generating process.
The Toyota production system includes a similar principle: genchi genbutsu or “go and see”. Get out on the shop floor or listen closely to the electrical lineman with twenty years’ experience.
Map process and data flows while validating facts. Experience shows that capturing what people think occurs often differs from reality. This is particularly true in post-merger environments or smaller businesses heavily reliant on in-house knowledge.
Visualize data to understand distributions, clusters, and outliers: the “shape of the data”. Collaborate with experts who can explain why data has these characteristics. If strong features cannot be explained, then consider rejecting use of the data set.
Study sensitivity between independent variables (those that affect the business result) and dependent variables (the answer to the business question). See which independent variables most affect outcomes. For example, if forecasting visitors to a zoo, new animals and day of the week will have more impact than gas price or promotions. In practice, business situations are usually less intuitive.
Check that organizing assumptions about data match reality. Look at time buckets: does a 24-hour day make sense in global capital markets? Is an hourly average number of visitors reasonable because it matches behaviors or is an hour simply a default way of thinking?
Watch for tendencies to only use internal data. If a business question optimizes external interaction, then look for factors influencing external behaviors. For example, our team collaborated with airlines which priced airfare based on monthly forecasts and observations of competitors. Extending pricing algorithms to include web traffic patterns and real time competitive pricing produced immediate results.
Finally, consider the complete lifecycle of the subject of the business question. Continuing with diesel engines, we see manufacturers can treat marketing, sales, quality, and aftermarket as silos. The full 360 of customer experience with an engine includes pre-sales activities in CRM, quality data in ERP, and aftermarket parts orders at dealers. Ensure that a model reflects the overall system.
2. Model
- Build training data.
Training data generally demands the most time of any project step. Models reproduce how business questions are answered in training data, so trusted training data is critical.
Product managers or business process owners should design training data. Identify needed scenarios, outcomes, and edge cases. Consider building a model routing messages to a contact center. Training data should include messages from each channel such as voice and text, use different communication styles, and include all types of customer intents and questions.
Labeling training data can require key people such as the top customer service reps or senior engineers. In smaller companies, we find that founders and leaders can bring strong views on labeling. If an expert stakeholder brings influential views on how to answer the business question, then ask them to label a substantial portion of training examples.
Leaders always ask “how many examples do we need?” and are disappointed there is no hard and fast rule. That’s the role of the next step, the calibration model. However, a useful guideline is the distribution of scenarios in training data should roughly reflect proportions in the real world. However, every scenario or outcome should form at least 10% of the training data set.
- Create a calibration model.
Create a pilot model early to build understanding of the process and confirm suitability of training data. Explain that the goal of a pilot model is to build understanding of the process and find needed refinements in training data but not to achieve high precision. However, early pilots can often build confidence when people see the results possible even with incomplete training data applied to stock open source algorithms.
Use the calibration model to identify where accuracy needs to improve, then adjust the training data. Machine learning projects can sometimes be the first time a business looks at how they make decisions. Clients don’t always know or want to acknowledge biases or inaccuracies in human decisions. These get reflected in training data.
- Iterate to reach a production model.
Evolving the calibration model into a finished product includes refining and correcting training data, shaping which data and how derived summaries are applied to the model (dimensionality reduction and data shaping), and adjusting the technical configuration (hyperparameters) of the model.
3. Results
- Build overall application.
Models are generally embedded within a business process or application. The user interface, logic, and data models should be started early. The calibration model should use an early version of the application intended for production. Treat the model and surrounding software as an agile project with frequent confirmation from business sponsors.
- Communicate how the model helps.
Achieving results depends on influencing change more than elegant math. Communicate how machine learning improves jobs and brings value to customers. Without communication, doubt will grow. Many models can be perceived as threatening jobs when they actually shift time to more fulfilling work. Communicate frequently to ensure messages are effectively received.
- Sustain capabilities.
Confirm business leaders understand that while machine learning can continually improve, this does not happen automatically. Product managers or process owners must continually refine training data. Also, build understanding of model drift where the underlying assumptions about the real world change. For example, a model forecasting consumer behaviors prior to Covid-19 may not match behaviors in later 2020.
Explicitly document that the team has needed skills to sustain models. We have seen consultants guilty of building support for new techniques, then leaving. Check that:
- IT task are automated. Many actions for quality assurance, configuring infrastructure, and deploying code should be driven by scripts rather than performed manually.
- If an organization is newer to cloud, hire experienced talent and have IT people earn certifications. In highly regulated industries, stress that certification provides evidence to regulators of project control.
- Product managers and business process owners understand algorithms and actively own a roadmap for evolving machine learning applications.
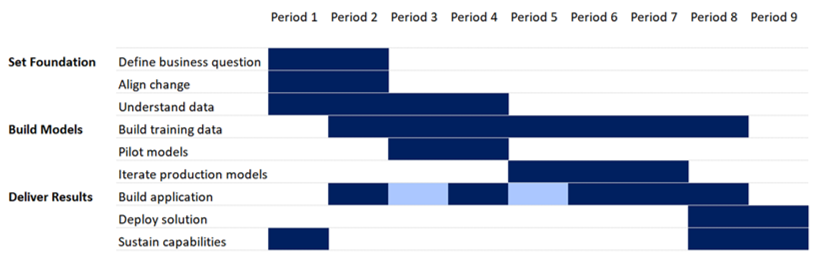
Project Structure
This chart shows concurrency and proportions of stages and tasks. Most time is spent understanding the data generating process and creating training data.
What’s Next?
Conversations with innovative companies show increased awareness of cognitive bias. In first generation projects, clients often assumed human decisions were optimal and sought to replicate these. Now, businesses think more about how decisions are made.
Second, expect digital twins of business processes. Digital twins are widely used with complex machines, such as jet engines, to quantify how design and usage affects reliability and efficiency. Similarly, process digital twins show how inputs affect results. For example, the alternatives investing arm of a leading asset manager intends to identify why they declined investments that later showed positive outcomes.
Finally, we see natural language increasingly used to interact with models. This will lead to conversations with business process digital twins: “Hey Sales, what would be the likely effect of a free shipping promotion?” or “New Merchant Onboarding, what’s the top reason requiring more than three days to start accepting payments on our platform?”. This requires that methodologies include a dictionary of terms and map how they relate (ontology).
Conclusion
Machine learning has moved from exploration to a mainstream business tool. Methodology similarly needs to shift from learning possibilities to delivering results. The Machine Intelligence methodology progressively builds understanding and alignment across a business, reduces uncertainty through rigor and iteration, and forms enduring capabilities to sustain results.